📄 Native DOCX & DOC Scraping (June 19th)
Our Markdown, HTML, and crawl APIs now natively scrape HTML, XML, JSON, text, CSV, Markdown, SVG, and PDF — and as of today, DOCX and DOC files too. Point any of these endpoints at a Word document and get clean, structured output back without extra conversion steps.🏷️ Page Metadata on Scrape & Crawl Responses (June 18th)
The/web/scrape/html, /web/scrape/markdown, and /web/crawl responses now include a metadata object (PageMetadata) extracted from the page’s <head> — title, description, language, canonical URL, Open Graph and Twitter tags, JSON-LD, and more — each carrying sourceUrl (requested) and finalUrl (scraped after redirects). Metadata is read from the unfiltered document, so includeSelectors/excludeSelectors no longer blank out title/meta fields, and relative links, images, and PDF references now resolve against finalUrl for more accurate output.📊 Hourly Usage for Today & Yesterday (June 17th)
The usage page now shows hourly usage for today and yesterday, giving you a more detailed view of recent API calls and credit consumption throughout the day.🗜️ GZIP Response Compression (June 17th)
Context.dev now supports GZIP response compression across the API. SendAccept-Encoding: gzip or use a client that negotiates gzip automatically to reduce transfer size on large responses, especially /web/scrape/html, /web/scrape/markdown, and /web/crawl. In scrape benchmarks, gzip cut bytes on the wire by about 82% and improved latency on large payloads. See the new Compression guide for setup and verification examples.🧭 Clear 404 Errors for Scrape & Crawl (June 16th)
The/web/scrape/html, /web/scrape/markdown, and /web/crawl endpoints now surface missing pages as a dedicated 404 error type. Previously, these cases were grouped under WEBSITE_ACCESS_ERROR, which made debugging harder when the target page simply did not exist.⚡ Lightning-Fast Usage Logs (June 16th)
We’ve significantly improved usage page performance, especially for organizations viewing millions of logs. Large usage histories now load and filter much faster, making the page feel lightning fast even at very high volume.🤝 Context.dev Affiliate Program (June 14th)
We’ve launched the Context.dev affiliate program — earn 25% per sale for a full year on every customer you refer. Read more in our launch announcement.🛝 API Playground Response Export & “Try in Cursor” (June 12th)
The Raw Response view in the developer API playground now matches the on-brand styling of the request code block, with a Copy button pinned to the top-right corner and a new dropdown beside it: Export JSON downloads the full response as aresponse.json file, and Try in Cursor opens Cursor with a pre-filled prompt containing the response so you can start building against the API immediately.🖥️ Official context-dev CLI (June 11th)
The official context-dev CLI is here, wrapping every Context.dev endpoint in a single binary — resolve brands, scrape pages to Markdown, take screenshots, extract styleguides and products, and classify industries straight from the terminal. Prebuilt binaries for macOS, Linux, and Windows ship with every GitHub release (shell completions and man pages included), or install with go install on Go 1.22+.Output is pipe-friendly: --format picks the encoding (JSON, YAML, pretty, interactive explore), and --transform reshapes responses with GJSON paths before they’re printed. Because it’s just a shell command, any coding agent can use it too — see the new Install the CLI guide for setup, per-endpoint examples, and a copyable agent prompt.⏳ Better 429 Rate-Limit Responses (June 11th)
Rate-limited (429) responses now include thekey_metadata object (credits_consumed is always 0 — throttled requests are never charged — plus your credits_remaining) and a Retry-After header telling you how many seconds until your per-minute window resets. The 429 response is now also fully documented in the OpenAPI spec across all API operations, so generated client types include the rate-limit contract.💳 key_metadata in All API Responses (June 11th)
Every JSON response now includes a key_metadata object when a valid API key is provided, with credits_consumed (credits used by the request) and credits_remaining (balance after the request). It’s included on all status codes — including handler errors, validation errors (400), and timeouts (408) — while responses to invalid keys (401) omit it.🔍 Status Code Filter for API Usage Logs (June 11th)
The usage logs page on the dashboard now includes a status code filter, so you can filter your API call history by HTTP status code (2xx, 3xx, 4xx, 5xx). This makes it much easier to track down failed requests and debug issues with your integration.🧠 Improved Web Extraction Pipeline (June 11th)
We’ve significantly improved our web extraction pipeline. Extractions are now more accurate and more reliable across a wider range of websites — no changes needed on your end, all/web/extract requests benefit automatically.📚 Documentation Refresh (June 10th)
We’ve updated our documentation with a fresh new look and brand new AI-native content. The docs are now easier to navigate, nicer to read, and better suited for both humans and AI agents building with Context.dev.🔑 API Key Usage Breakdown (June 9th)
API calls history now includes a “By Key” breakdown, so you can view call and credit usage by API key. The chart reuses the existing usage aggregation logic and shows API key names when available, with key IDs as fallbacks.🎯 HTML Selector Filters for Scrape & Crawl (June 8th)
Theweb/scrape/html, web/scrape/markdown, and web/crawl endpoints now accept includeSelectors and excludeSelectors CSS-selector parameters to narrow scraped content down to exactly what you need.Use includeSelectors to keep only matching subtrees (returned as a subtree union in document order) and drop everything else, and excludeSelectors to remove matching elements afterward; exclusion always wins when an element matches both. Selectors are validated up front (invalid CSS returns INPUT_VALIDATION_ERROR / HTTP 400 before any scraping), capped at 50 selectors per list and 2048 characters each. Filters apply only to HTML-like content (non-HTML like PDF and XML is returned untouched), and selector values are part of the scrape cache key so different selectors are cached separately. The OpenAPI spec and generated API types have been updated to document the new parameters.🗺️ Native XML Conversion for XSL Sitemaps & Feeds (June 7th)
The Scrape HTML endpoint now natively handles XML conversion, so XSL-styled sitemaps and feeds are surfaced as raw XML with a detected content type instead of Chrome’s rendered HTML viewer.When a page is served as XML (like an XSL-styled sitemap), we now recover the raw XML and re-fetch the non-JS-rendered document so you get the underlying markup. The Scrape HTML response now includes atype field ("html" | "xml" | "json" | ...) so you can tell what kind of content was returned, and the OpenAPI spec and generated API types have been updated to match.🧾 headers Parameter for Web Scraping (June 6th)
The web scraping endpoints now support an optional headers query parameter for forwarding custom outbound HTTP headers to the target URL. Send headers as deep-object query params such as headers[X-Custom]=value; when headers are provided, caching is bypassed so requests always use the supplied header values.Use it to pass a custom User-Agent, cookies, authorization headers, locale hints like Accept-Language, or any other target-site headers your scrape needs. All SDKs have been updated with support for the new headers parameter.🚀 Context.dev is Backed by Y Combinator (June 1st)
Context.dev is now backed by Y Combinator. We’re excited to keep building the web intelligence layer for developers, AI products, and automation teams with YC’s support.May 2026
Structured Web Extraction API, Web Search API, Rate Limits, SOC 2, Go SDK & Web Endpoint Controls
🧠 Structured Web Extraction API (May 31st)
NewPOST /web/extract endpoint for extracting structured data from websites with your own JSON Schema. The older /brand/ai/query endpoint is now deprecated in favor of /web/extract, but it will stay live for the foreseeable future, so there is no need to migrate right away. New builds should prefer /web/extract.⚡ Better Caching & Web Search Controls (May 30th)
You now have better caching controls in the Fonts and style guide demos, including quick 1-day, 7-day, and 30-day presets on the developer API playground. We also updated all code examples (cURL, JavaScript/TypeScript, Ruby, Python, and Go) so it’s easier to use caching in your own implementation.Web Search now supports more Markdown and PDF parsing controls, plus request timing options likewaitForMs, maxAgeMs, and timeoutMS. We also updated the docs and SDKs to cover the existing pricing-page targeting option in AI Query (specific_pages.pricing) and to reflect all new options.⏱️ Per-Minute Rate Limits (May 25th)
Rate limits have moved to a per-minute basis and are now surfaced directly on the dashboard so you can see your plan’s limit at a glance. Updated limits: Free 10 requests/min, Starter 120 requests/min, Pro 300 requests/min, Scale 1,200 requests/min. See the rate limits page for full details.🔎 Web Search API (May 16th)
NewPOST /web/search endpoint for web search with optional per-result Markdown scraping in one request. Use domain filters, freshness windows, query expansion, and Markdown options to control recall and extraction.🔐 SOC 2 Type I Compliance (May 14th)
Context.dev is now SOC 2 Type I compliant. SOC 2 Type II is pending the end of its observation period, and you can follow our current security and compliance status in the Context.dev Trust Center.🧩 Go SDK Launch (May 14th)
The official Go SDK is now available. Install it withgo get github.com/context-dot-dev/context-go-sdk and use contextdev.NewClient to access Context.dev from Go 1.22+ projects.🍪 Cookie Popup Handling for Screenshot Endpoint (May 11th)
The screenshot endpoint now supports an optionalhandleCookiePopup query parameter. Set handleCookiePopup=true to dismiss cookie or consent banners before capture; omit it or set it to false to capture the page without that extra step.📄 New pdf Controls for PDF Parsing (May 10th)
The web scraping endpoints now support a backwards-compatible pdf parameter, replacing parsePDF with richer controls for PDF handling. Use pdf.shouldParse, pdf.start, and pdf.end to steer whether PDF files are parsed and limit extraction/OCR to a specific page range.⏱️ New stopAfterMs Steering Parameter for Web Crawl (May 10th)
The /web/crawl endpoint now supports a stopAfterMs parameter, giving crawls a soft time budget. After each page scrape, the crawler checks elapsed time and returns the pages collected so far if the budget has been exceeded. Defaults to 80 seconds (80000 ms), with supported values from 10 seconds (10000 ms) to 110 seconds (110000 ms).⏱️ waitForMs Support Across Web Endpoints (May 8th)
Most web endpoints now support a waitForMs parameter, giving you finer control over how long scraping waits for pages to load dynamic content before returning results.📸 Screenshot Endpoint Upgrades (May 7th)
The screenshot endpoint now supports configurable browser dimensions and amaxAgeMs parameter to control cached screenshot freshness. Screenshot responses now also include width and height for the returned image, so you can size and lay out screenshots without an extra round trip.⏱️ New maxAgeMs Parameter for Brand Endpoints (May 6th)
The brand endpoints, including /brand/retrieve, now support an optional maxAgeMs parameter to control how long cached brand data may be reused before the API performs a hard refresh. Defaults to 3 months (7776000000 ms); values below 1 day are clamped to 1 day, and values above 1 year are clamped to 1 year. Warning: this may increase latency if set.🖼️ Cached Results & Image Enrichment for /web/scrape/images (May 5th)
The /web/scrape/images endpoint now supports cached results and optional image enrichment. By default, recent image scrape results may be reused for up to 24 hours; use maxAgeMs=0 to force a fresh scrape, or set a custom cache window up to 30 days.New enrichment options let you request image dimensions, hosted media.brand.dev URLs, MIME types, and asset classification for scraped images. Classification can identify assets such as photography, illustrations, logos, word marks, icons, patterns, graphics, and other image types.Pricing remains 1 credit for standard image scrape requests. Requests with any enrichment option enabled cost a flat 5 credits per call.✍️ Improved Word Mark Detection (May 3rd)
Word mark extraction has been dramatically improved: we now reliably capture word marks composed of an image logo paired with text in a specific layout from any website.🖼️ includeFrames Parameter for Web Scraping Endpoints (May 1st)
The /web/scrape/html, /web/scrape/markdown, and /web/crawl endpoints now support an optional includeFrames parameter (default: false) that waits for iframe content to render and embeds it directly in the response, so embedded widgets, video players, and third-party docs are captured.🛠️ API Playground Improvements (April 27th)
Every endpoint in the developer portal API playground now links to its full docs page, and all parameters are configurable directly from the UI.📈 Usage Dashboard Upgrades (April 25th)
Usage logs are now fully paginated (30/page) with access to your complete request history, and the path filter spans every endpoint your org has ever called. The usage chart drops the 8-path cap, adds an “All Time” range with day/month grouping for longer windows, and supports an interactive legend to toggle paths or statuses on and off.🏭 New SIC Classification Endpoint (April 25th)
NewGET /web/sic endpoint that classifies any brand into Standard Industrial Classification (SIC) codes from a domain or name. Choose between the original 1987 SIC system (original_sic), which is still used heavily across the US, or the latest pruned SIC list maintained by the SEC (latest_sec).🏷️ New sku Field on Product Endpoints (April 23rd)
The POST /brand/ai/products and POST /brand/ai/product endpoints now return a sku field on every product, giving you a reliable identifier to match products across your systems, track inventory, and remove duplicates across retailers. Consulting and software product types return sku: null.📄 PDF Support for Web Scraping Endpoints (April 23rd)
The/web/scrape/html, /web/scrape/markdown, and /web/crawl endpoints now handle PDF URLs natively.- New
parsePDFparameter (default:true) — when set tofalse, PDF URLs are skipped and return a 400 response instead of attempting extraction. - Structured output — PDF content is extracted and returned as
<html><pdf>…</pdf></html>, consistent with HTML scrape responses. - Automatic OCR — scanned PDF files with low text yield are automatically routed through OCR, and embedded images inside PDF files are automatically detected and processed with OCR to maximize text coverage.
numSkippedon crawl responses —/web/crawlresponses now include anumSkippedcounter reflecting pages skipped due to PDF filtering or URL regex rules.
⏱️ New maxAgeMs Parameter for Web Crawl Endpoint (April 23rd)
The /web/crawl endpoint now supports an optional maxAgeMs parameter to serve cached crawl results within a specified age, improving performance for repeated requests.🔤 New fontLinks Field on Fonts & Style Guide Endpoints (April 21st)
The /web/fonts and /web/styleguide endpoints now return a fontLinks object containing downloadable font file URLs keyed by family name. Each entry is typed as google or custom, exposes upright font files keyed by weight (e.g. "400", "500", "700"), and includes a Google Fonts category or a human-readable displayName for custom fonts, so clients can match a fontFamily/fontWeight directly to a concrete file URL.🔍 New urlRegex Parameter for Sitemap Endpoint (April 19th)
The /web/scrape/sitemap endpoint now supports an optional urlRegex query parameter to filter which URLs are collected during a sitemap crawl.📊 Usage Page & Logs Upgrades (April 16th)
The usage page on the developer portal now shows credits over time in addition to the existing API calls over time, plus a new breakdown of which paths you’re calling most often. We also added the ability to search through your logs by input, and it’s lightning fast. On top of that, UX improvements have been shipped across the usage page and the homepage of the developer portal.🔑 Multiple API Keys on the Developer Dashboard (April 11th)
The developer dashboard now supports creating and managing multiple API keys per account, making it easier to separate environments, rotate credentials, and scope access across projects.🔗 New directUrl Parameter for Screenshot Endpoint (April 9th)
The screenshot endpoint now supports a directUrl parameter to screenshot a specific URL directly, bypassing domain resolution.💬 Expanded Social Media Support (April 7th)
Brand social links now include WhatsApp, Telegram, and Line, which brings the total supported platforms to 31.🌐 New primary_language Field on All Brand Endpoints (April 5th)
All brand endpoints now return a primary_language field indicating the primary language of the brand’s website content, detected from HTML lang tags, page content analysis, and social media descriptions.🕷️ New Web Crawl Endpoint (April 4th)
NewPOST /web/crawl endpoint that crawls an entire website and returns every page as clean Markdown. Point it at any URL and it will follow same-domain links across up to 500 pages, giving you a massive amount of structured context from a site in a single API call. Each successfully crawled page costs 1 credit.The endpoint supports maxPages, maxDepth, urlRegex filtering, useMainContentOnly for stripping nav/footer chrome, and followSubdomains for broader coverage. Response metadata includes per-page status codes, crawl depth, and success/failure counts so you know exactly what you got back.⚡ Major Style Guide Endpoint Overhaul (April 3rd)
Massive performance improvements to the/web/styleguide endpoint (formerly /brand/styleguide): p50 latency is now 6 seconds. The prioritize parameter has been removed since we now handle prioritization natively. Additionally, some objects in the response now include a css field with ready-to-use CSS, along with other new return parameters for richer data extraction.📄 Scrape Markdown: useMainContentOnly Parameter (March 28th)
The /web/scrape/markdown endpoint now supports a useMainContentOnly parameter to extract only the main content of a page, excluding headers, footers, sidebars, and navigation.🖼️ Scrape Images: Background Image Support (March 25th)
The/web/scrape/images endpoint now extracts CSS background images in addition to standard image elements, for more complete image coverage from any page.🗺️ Sitemap maxLinks Parameter (March 25th)
The sitemap endpoint now supports a maxLinks parameter, letting you control how many links are crawled (min 1, max 100,000). (The response urls[] array is still capped at 500 URLs.) We plan to raise the upper limit based on customer feedback.🚀 Brand.dev is Now Context.dev (March 21st)
We’ve changed from Brand.dev to Context.dev to reflect the full scope of what we provide: context for software, web apps, and AI agents. All existing integrations remain fully backwards compatible with no code changes required. Brand data remains a first-class citizen alongside our expanded capabilities in AI-powered extraction, product intelligence, and custom web queries.Entries below this point predate the rebrand; product names and links have been updated retroactively to Context.dev.🖼️ Improved Logo Detection (March 20th)
Improved logo detection to filter out icon shapes that are clearly not logo-like, reducing false positives in extracted brand assets.🌍 Country Parameter for Name Search (March 17th)
Addedcountry_gl to /brand/retrieve-by-name. It lets you specify a country code so you get the right company when the same name exists in multiple countries.💳 New Pricing: API Credits (March 8th)
We’re switching from flat API calls to a credit-based system.Nothing is getting more expensive.This just lets us charge less for lighter operations. The web scraping endpoints? 1 credit each. That’s 1/10th the cost of a standard API call.Your existing quota converts directly: 3,000 calls becomes 30,000 credits. Same or better value across the board.🎛️ Web Scraping Endpoints Added to Dashboard (March 7th)
 The four new web scraping endpoints are now visible and testable directly from the developer dashboard.
The four new web scraping endpoints are now visible and testable directly from the developer dashboard.🕸️ New Web Scraping Endpoints (March 6th)
We’ve released four new web scraping endpoints, giving you direct access to raw page content from any URL.GET /web/scrape/html— Scrapes a URL and returns the raw HTML content of the page. Uses automatic proxy escalation to handle blocked sites.GET /web/scrape/markdown— Scrapes a URL and converts the HTML to markdown. Supports options to include/exclude links and images.GET /web/scrape/images— Extracts all images from a URL, including inline SVG files, base64 data URI strings, and standard image URLs acrossimg,svg,picture,link, andvideoelements.GET /web/scrape/sitemap— Crawls a domain’s sitemap and returns all discovered page URLs (up to 500). Supports sitemap index files, parallel fetching, and automatic duplicate removal.
🎯 high_confidence_only for Transaction Identification (February 28th)
The GET /brand/transaction_identifier endpoint now supports a high_confidence_only query parameter (boolean, default: false). When set to true, the API runs extra verification steps so the identified brand matches the transaction with high confidence.🔗 directUrl for Style Guide Extraction (February 23rd)
The GET /web/styleguide endpoint (formerly /brand/styleguide) now supports a directUrl query parameter. Use it to fetch a specific page directly (e.g., a design system or style guide URL) instead of providing a domain. Either domain or directUrl is required, not both.⚡ Infra Performance Boost (February 22nd)
Infrastructure improvements deliver a 20% latency reduction across all API endpoints. Your requests should feel noticeably faster.🖼️ New images Field for Product Extraction (February 22nd)
The POST /brand/ai/products and POST /brand/ai/product endpoints now return an images array on each product. This field contains URLs to product images found on the page (up to 7 images per product), in addition to the existing image_url field for the primary image.Updated Product Schema:images— Array of image URLs from the product page (up to 7)image_url— Primary product image URL (unchanged)
📈 Quota Increase for Plans (February 10th)
We’ve had a major breakthrough in reducing our infrastructure costs, and we’re passing the savings directly to you with increased quotas at no additional cost.Updated Quotas:- Starter — 2,000 → 3,000 calls/month
- Pro — 10,000 → 20,000 calls/month
- 1,000 or 1,500 call plans → 3,000 calls/month
- 15,000 call plans → 20,000 calls/month
🛒 New Single Product Extraction Endpoint (February 8th)
We’ve released a new beta endpoint to extract product information from a single URL. The newPOST /brand/ai/product endpoint determines if a given URL is a product detail page, classifies the platform, and extracts structured product data.New Endpoint:POST /brand/ai/product- Extract a single product from a URL
- Amazon
- TikTok Shop
- Large marketplace sites
- Generic ecommerce sites
- Product name, description, and category
- Price, currency, and billing frequency
- Pricing model (per seat, flat, tiered, free tier, custom)
- Features, target audience, and tags
- Product image URL
🛍️ New directUrl Parameter for the Extract Products API (February 7th)
The extract products endpoint now supports a directUrl parameter, allowing you to pass a direct link to a shop page for product extraction. This is useful for extracting products from marketplace shops such as TikTok Shop, eBay stores, Amazon storefronts, or any other direct URI.New Parameter:directUrl- A specific URL to use directly as the starting point for product extraction, bypassing domain resolution
🔗 Logo Link Now Live (February 1st)
Logo Link is now available! Easily link logos to their brand pages with our new Logo Link feature.Check out Logo LinkJanuary 2026
Docs Revamp, Make Integration, AI Products API, Dashboard Redesign & Performance Improvements
📚 Documentation Revamp (January 31st)
We’ve revamped our entire documentation to be more user-friendly with improved guides, making it easier than ever to get started and find what you need.🔌 Make Integration Now Live (January 25th)
Our Make integration is now available! Connect Context.dev with thousands of apps using Make’s powerful automation platform.Check out the Make integration🐛 Social Links Bug Fix (January 15th)
Fixed an issue where generic social links (e.g.,https://x.com/) were being returned when they weren’t tightly correlated with the brand.🎨 Complete Dashboard Redesign (January 14th)
We’ve launched a complete redesign of the developer dashboard with a fresh new look and improved user experience.🛍️ New AI Products Extraction API (January 5th)
We’ve released a new beta endpoint to extract product information from any brand’s website! The AI Products API uses advanced AI to analyze websites and return structured product data including pricing, features, target audience, and more.New Endpoint:POST /brand/ai/products- Extract products from a brand’s website
- Product Details - Get name, description, category, and image URL for each product
- Pricing Information - Extract price, currency, billing frequency (monthly/yearly/one-time/usage-based), and pricing model (per-seat/flat/tiered/free-tier/custom)
- Rich Metadata - Retrieve features list, target audience, and tags for each product
- Customizable Results - Control the maximum number of products to extract (1-12)
- Product name and description
- Price, currency, and billing frequency
- Pricing model type
- Product URL and image URL
- Category classification
- Features array
- Target audience array
- Tags array
🎛️ Developer Dashboard Updates (January 3rd)
We’ve updated the developer dashboard to display the new endpoints added in recent months:- Retrieve by Email - Now visible in the dashboard endpoint list
- Get Fonts - Font extraction endpoint now shown in the dashboard
🎆 Happy New Year! Performance Improvements (January 1st)
Happy New Year! 🎉We’re kicking off 2026 with a significant performance improvement: the p50 latency for cold hits on the/brand/retrieve endpoint is now down to 7 seconds, thanks to continued infrastructure optimizations and caching improvements.This represents a substantial improvement from our previous 9-second p50, making brand data retrieval even faster for all your applications.⚡ New Email Preload Endpoint (December 22nd)
We’ve released a new preload endpoint that accepts an email address, extracts the domain, and queues it ahead of future requests to improve latency. This endpoint doesn’t count against your quota and is available for paid customers to optimize their API performance.It will immediately return a 422 if the email is a free or disposable email.View the endpoint documentation🖼️ Improved Backdrops Processing (December 15th)
We’ve improved our image processing pipeline to remove duplicate backdrops, ensuring cleaner and more efficient image data.🏭 Enhanced NAICS Industry Classification (December 14th)
We’ve significantly improved our NAICS industry classification endpoint with new parameters and enhanced accuracy. The classification system now provides more control and better insights into how well each NAICS code matches a brand.New Parameters:minResults- Minimum number of NAICS codes to return (1-10, defaults to 1)maxResults- Maximum number of NAICS codes to return (1-10, defaults to 5)
confidence- Each NAICS code now includes a confidence level (high,medium, orlow) indicating how well the code matches the company description
- Dramatically improved classification accuracy through enhanced algorithms and better data processing
- More reliable industry classification for better business intelligence and data analysis
📞 New Phone Parameter for Transaction Enrichment (December 10th)
We’ve added a new optionalphone parameter to the Transaction Enrichment endpoint to help dramatically increase identification accuracy when Visa/Mastercard returns phone number data in transaction information.New Parameter:phone- Optional phone number from the transaction to help verify brand match
🚀 AI Query Enhancements (November 30th)
AI Query Improvements:- Added pricing page analysis support in
specific_pagesparameter - Enhanced list extraction with
datapoint_list_typeanddatapoint_object_schemaparameters - Now supports arrays of objects in addition to primitive arrays
🔤 New Font Extraction API (November 29th)
We’ve released a new beta endpoint to extract font information from any brand’s website! The Font API provides comprehensive typography data including font families, usage statistics, fallbacks, and element/word counts.New Endpoint LinkKey Features:- Font Families - Get all font families used on the website
- Usage Statistics - See where fonts are used with CSS selectors and element types
- Fallback Fonts - View fallback font families for each font
- Usage Metrics - Get element counts, word counts, and percentage statistics for each font
- Font family names
- Array of CSS selectors/element types where each font is used
- Fallback font families
- Number of elements and words using each font
- Percentage of words and elements using each font
🦃 Happy Thanksgiving! Brand Update Requests (November 27th)
Happy Thanksgiving! 🦃We’re excited to announce our new brand update request page! You can now request an update to any brand and we’ll get to it within 24 hours or less. Whether you need to update your logo, colors, or any other brand information, simply submit a request and we’ll handle it quickly.🎯 Transaction Enrichment Parameters (November 24th)
We’ve added three new optional parameters to the Transaction Enrichment endpoint to improve transaction identification accuracy:mcc- Merchant Category Code (4-digit code) for business category contextcity- City name to prioritize local branches or regional variationscountry_gl- ISO 3166-1 alpha-2 country code for geographic prioritization
🔢 New Retrieve-by-ISIN Endpoint (November 18th)
We’ve added a new endpoint to retrieve brand data by ISIN (International Securities Identification Number). This endpoint allows you to look up companies using their ISIN and returns comprehensive brand information.New Endpoint:/brand/retrieve-by-isin- Retrieve brand information using an ISIN
- Supports all ISIN formats (e.g., ‘AU000000IMD5’, ‘US0378331005’)
- ISIN must be exactly 12 characters: 2 letters followed by 9 alphanumeric characters and ending with a digit
- Returns the same comprehensive brand data as other retrieve endpoints
- Supports all standard parameters including
force_language,maxSpeed, andtimeoutMS
💰 Fairer Charging Model - Only Pay for Success (November 16th)
We’ve changed the way we charge and will only charge on successful 200 status code responses.This means no more charges for:- Bad domains
- Invalid inputs
- Bad emails (free or disposable email providers) for retrieve by email endpoint
🎯 Demo Experience & Website Updates (November 15th)
We’ve improved the demo experience to show bad inputs in a more informative way, fixed blog 404 pages, and updated all links on our main website to reflect the updated docs.🔐 GitHub Login and Sign-Up Support (November 10th)
You can now sign up and log in to your account using GitHub!🎃 Happy Halloween! New Email-Based Brand Retrieval Endpoint (October 31st)
Happy Halloween! 👻We’ve released a new endpoint to retrieve brand data by email address! This endpoint automatically extracts the domain from the email address and returns brand data for that domain. Best of all, it automatically returns an appropriate error if the email is from a free email provider (like gmail.com, yahoo.com) or a disposable email address, saving you from unnecessary processing.Check out the new endpoint documentation📚 Split Retrieve Endpoint for Better Documentation (October 29th)
We’ve split our retrieve endpoint into three separate endpoints to make the documentation much easier to read and understand:retrieve- The original endpoint for retrieving brand data by domainretrieve-by-ticker- Dedicated endpoint for retrieving brand data by stock ticker symbolretrieve-by-name- Dedicated endpoint for retrieving brand data by company name
⚡ Infrastructure Improvements - 20% Speed Boost (October 25th)
We’ve released significant infrastructure improvements that have resulted in a 20% speed increase across all API requests.🎯 Reduced False Positives on Icon-like Logos (October 13th)
We’ve released an improvement that significantly reduces false positives when detecting icon-like logos, providing more accurate brand data extraction.🌍 Enhanced Stock Market Ticker Support with Exchange Selection (October 8th)
We’ve enhanced our brand data fetching capabilities for stock market ticker support by now allowing customers to specify the exchange they want to retrieve the ticker for. This gives you more precise control when working with international stocks and ensures you get the correct ticker data for companies listed on different exchanges worldwide.New Parameter:ticker_exchange- Optional stock exchange for the ticker. Only used when ticker parameter is provided. Defaults to assuming the ticker is American if not specified.
🔗 Screenshot Page Parameter Added to API playground (September 28th)
We’ve updated our API playground to account for the new “page” parameter added to the screenshot API.If provided, the system will scrape the domain’s links and use heuristics to find the most appropriate URL for the specified page type.The options are:login, signup, blog, careers, pricing, terms, privacy, and contact.🔗 Automation Integration 2.0.0 Released (September 27th)
We’ve released an updated Zapier integration (v2.0.0) with enhanced functionality and improved user experience. Check out the updated documentation to get started with the new version.TLDR: Updated retrieve brand action, 3 new actions, updated docs with recipes.📊 API History Feature Released in Beta (September 22nd)
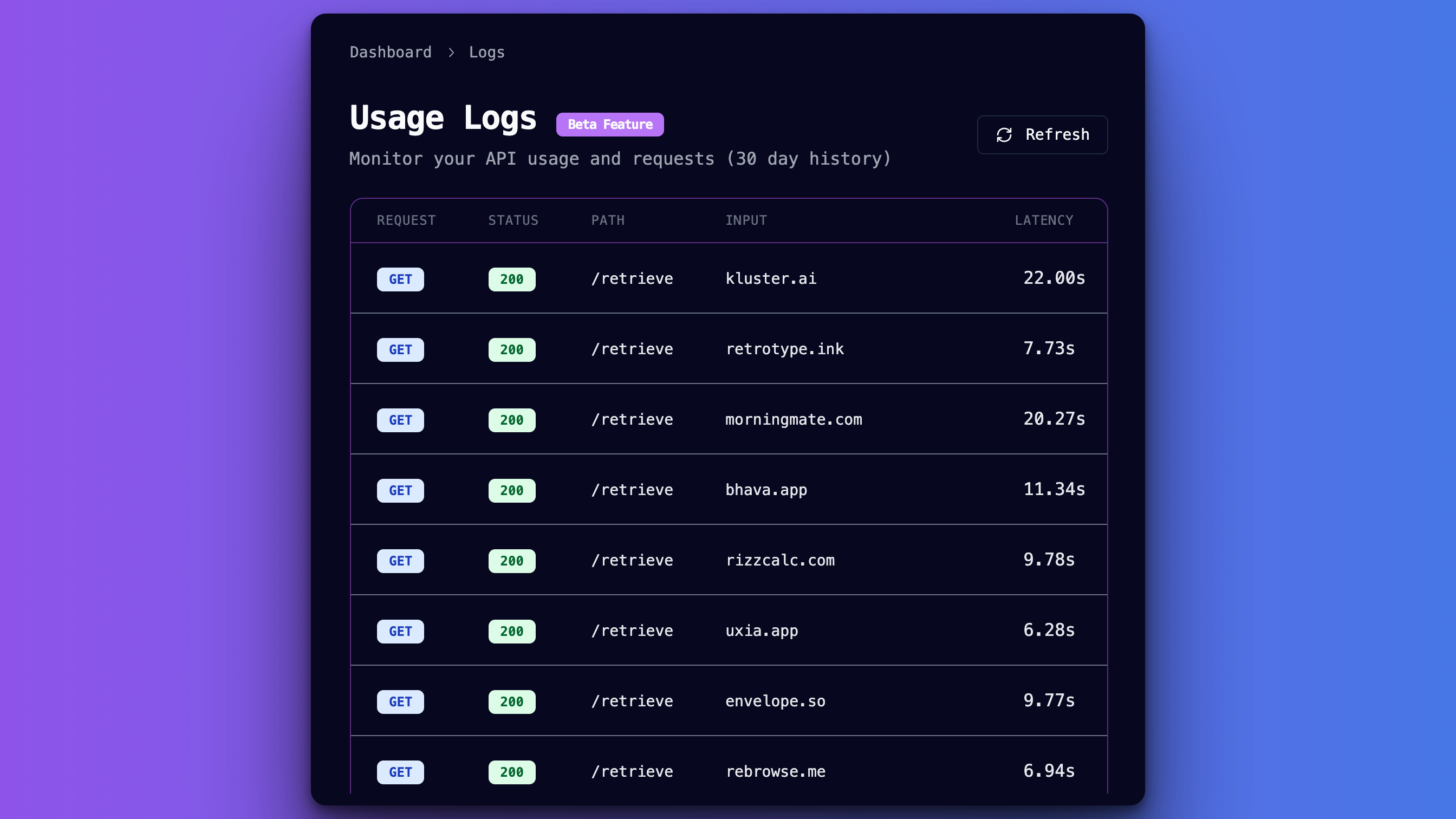 We’re excited to announce the beta release of our new “API History” feature on the dashboard! This powerful new tool gives you comprehensive visibility into your API usage patterns, helping you better understand your consumption trends and optimize your API calls.This feature is currently in beta, so we’re actively collecting feedback to improve the experience. Try it out and let us know what you think!
We’re excited to announce the beta release of our new “API History” feature on the dashboard! This powerful new tool gives you comprehensive visibility into your API usage patterns, helping you better understand your consumption trends and optimize your API calls.This feature is currently in beta, so we’re actively collecting feedback to improve the experience. Try it out and let us know what you think!🐛 History Analytics Graph Bug Fix (September 22nd)
We’ve fixed a critical bug in the dashboard’s history analytics graph that was causing display issues and incorrect data visualization. The graph now accurately shows your API usage patterns and analytics data, providing you with reliable insights into your API consumption.⚡ Retrieve Endpoint Performance Optimization (September 22nd)
We’ve released a significant performance update to our retrieve endpoint, reducing the p50 latency of cold hits to just 9 seconds. This improvement makes brand data retrieval faster and more responsive for all your applications.🎯 Enhanced API Control with New Parameters (September 15th)
We’ve added powerful new parameters to both our Screenshot and style guide APIs, giving you more control over how these endpoints behave and perform.📸 Screenshot API Enhancements
Newpage Parameter:- Automatically finds and screenshots specific page types using intelligent heuristics
- Supports 8 page types:
login,signup,blog,careers,pricing,terms,privacy,contact - Works across 30 supported languages for global website coverage
- If not specified, defaults to the main domain landing page
prioritize Parameter:- Choose between
speed(faster capture, basic quality) orquality(higher quality, longer wait times) - Defaults to
qualityfor optimal results - Perfect for balancing performance needs with output requirements
🎨 Style Guide API Enhancement
Newprioritize Parameter:- Same speed vs quality trade-off as the Screenshot API
- Defaults to
speedfor faster design system extraction - Optimize for your specific use case - quick prototyping or detailed analysis
⚡ Style Guide API Performance Boost (September 7th)
We’ve made significant performance improvements to our style guide API, reducing the p50 response time by 50% to just 18 seconds. This dramatic speed improvement means faster design system extraction for all your brand analysis workflows.🔗 Important Links Now Available on Retrieve Endpoint (September 7th)
We’ve released a new “links” feature under the brand retrieve endpoint that automatically pulls a domain’s key links including careers, blog, terms of service, privacy policy, and pricing pages. This makes it easier than ever to build comprehensive brand profiles and access important company information programmatically.New Response Field:Check it out herelinks- Object containing URLs for careers, blog, terms, privacy, contact, and pricing pages
🎉 Happy Labor Day & Pricing Update (September 1st)
Happy Labor Day to all our hardworking developers and customers! 🇺🇸We’ve updated our starter tier pricing to better reflect the infrastructure costs of our API. As always, all existing customers on the previous pricing plan have been grandfathered in, so there’s no price increase for current users.New customers will see the updated pricing on our website, while existing customers continue to enjoy their current rates. We appreciate your continued support and trust in our API!🧾 Invoice Management Now Available (August 31st)
You can now view and download invoices directly from the developer portal.🌐 Website Redesign & Developer Portal Integration (August 27th)
 We’ve completely redesigned our website and moved away from Framer into a fully custom NextJS landing page + blog. More importantly, the separate developer portal has been removed since it is now baked directly into the main website for a seamless experience - no more jumping between different domains to manage your account and access docs.
We’ve completely redesigned our website and moved away from Framer into a fully custom NextJS landing page + blog. More importantly, the separate developer portal has been removed since it is now baked directly into the main website for a seamless experience - no more jumping between different domains to manage your account and access docs.🛠️ Developer Portal Updates (August 21st)
Added seamless plan upgrades and downgrades without requiring cancellation first.🎮 API Playground Enhanced with Contact, Industry, NSFW Data (August 20th)
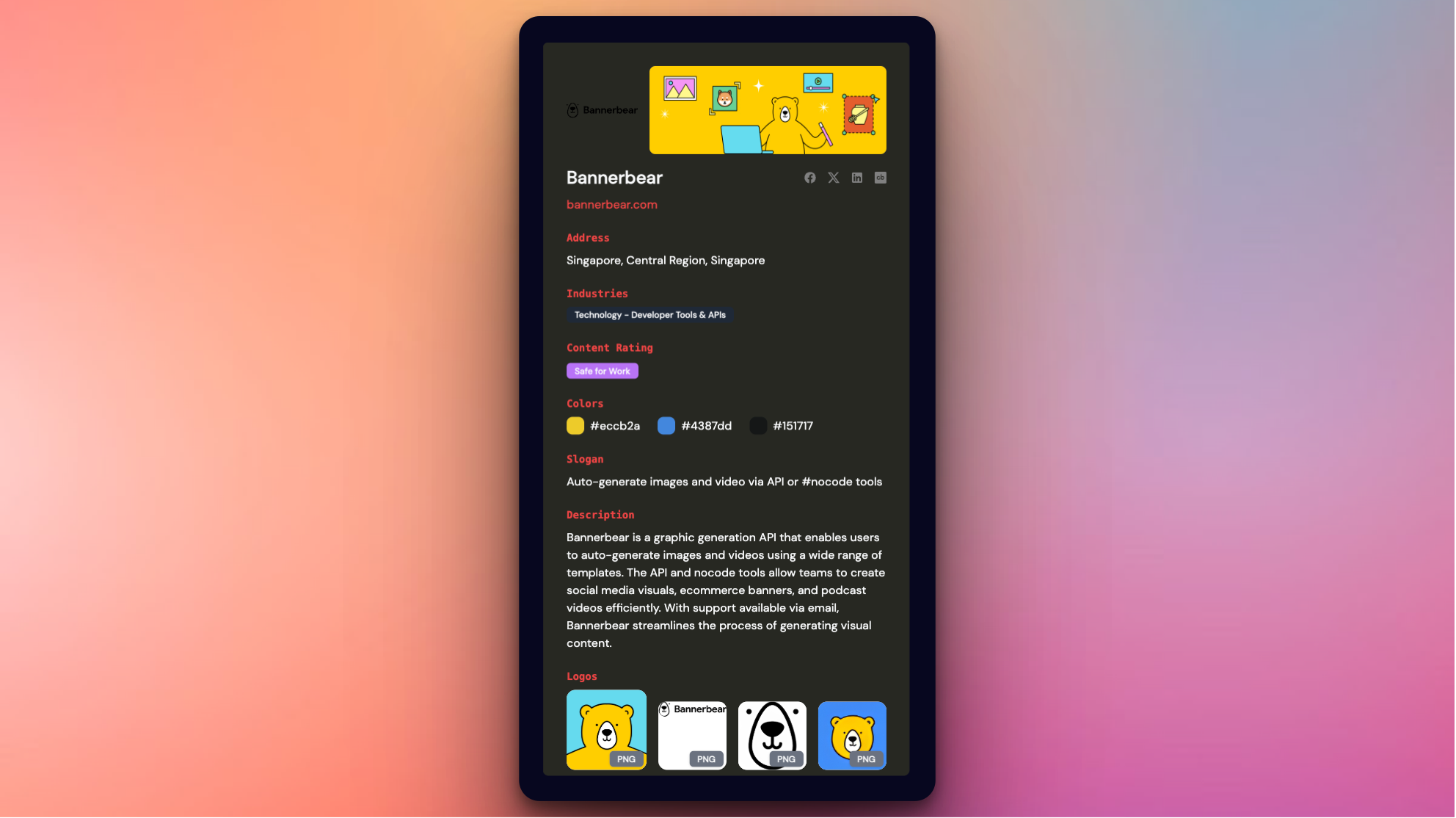 Enhanced our API playground to now showcase contact email, contact phone, industries, and all backdrops for a complete preview of available brand data.
Enhanced our API playground to now showcase contact email, contact phone, industries, and all backdrops for a complete preview of available brand data.🏭 EIC (Easy Industry Classification) Support (August 19th)
We’ve added EIC (Easy Industry Classification) support to our brand retrieve endpoint, providing you with standardized industry categorization for any brand. This feature helps you automatically classify companies into specific industries and sub-industries for better data organization and analysis.New Response Field:industries.eic- Array of industry classifications with both industry and subindustry information
🔍 Enhanced Retrieve Endpoint with Name & Ticker Support (August 18th)
We’ve expanded our retrieve endpoint to support fetching company data by name and ticker symbol, giving you more flexibility in how you access brand information.New Query Parameters:name- Company name to retrieve brand data for (e.g., ‘Apple Inc’, ‘Microsoft Corporation’). Must be 3-30 characters. Cannot be used with domain or ticker parameters.ticker- Stock ticker symbol to retrieve brand data for (e.g., ‘AAPL’, ‘GOOGL’, ‘BRK.A’). Must be 1-6 characters, letters/numbers/dots only. Cannot be used with domain or name parameters.
🖼️ Enhanced Word Mark Extraction (August 10th)
We’ve significantly improved our support for word mark extraction by updating our image pipeline and refreshing our brand database.- Updated Image Pipeline - Enhanced algorithms for better word mark detection and extraction
- Massive Data Refresh - Refreshed over 500K domains to extract word marks from their brand data
- Better Coverage - More brands now have accurate word mark representations available
🔧 API Key History Fix (August 4th)
Fixed a critical bug where rotating API keys would completely clear your call history. This update works retroactively as well.- Preserved History - API call history is now maintained across API key rotations
- Organization-Level Tracking - History is tied to your organization, not individual keys
- Seamless Key Management - Rotate keys without losing valuable usage analytics
🛡️ NSFW Content Detection (July 22nd)
We’ve added a newis_nsfw field to the brand retrieve endpoint to help businesses automatically detect and filter out pornographic or NSFW content, ensuring your platform stays safe and professional.Check it out in the documentation🖼️ Crystal Clear Logos (July 21st)
We’ve upgraded our image pipeline to ensure all returned logos are crisp, high-resolution, and ready for any display size.- Enhanced Resolution Detection - Our pipeline now prioritizes high-DPI logo sources
- Smart Resolution Enhancement - When needed, we intelligently enhance lower-resolution logos
- Quality Filtering - Automatically filters out blurry or low-quality logo variants
🚫 Search API Deprecation - Quality Over Quantity (July 20th)
Sometimes the hardest decisions are the right ones. We’ve made the tough call to deprecate our search API endpoint effective immediately.Why We’re Doing This:Let’s be honest - we believe in shipping features that actually work, not half-baked solutions that leave you frustrated. After extensive analysis, we discovered that our search API wasn’t meeting the quality standards we (and you) deserve. Rather than keep a subpar feature limping along, we’re pulling the plug to focus our energy on the APIs that truly deliver value.Our Philosophy:We’d rather have 5 rock-solid endpoints that you can rely on than 10 mediocre ones that make you question our competence. Quality over quantity isn’t just a buzzword for us - it’s how we sleep well at night knowing our API won’t let you down when it matters most.What This Means:- No More Search API - The endpoint is officially deprecated and will return a 410 Gone status
- Refocused Development - More resources dedicated to improving our core brand intelligence features
- Better User Experience - No more confusion about which endpoints actually work well
- Honest Communication - We’ll always tell you when something isn’t up to snuff
📝 Developer Portal Feedback Widget (July 19th & 13th)
Multiple customers have brought up the issue of bad company names being retrieved. We’ve updated our pipeline to catch this earlier and ensure all retrieved titles are immediately usable for display. We’ve also added a feedback widget to our developer portal to make it easier for you to share suggestions, report issues, and help us improve the API.
🛡️ Enhanced Error Handling & DDoS Protection (July 10th)
We’ve significantly enhanced API error handling capabilities and implemented robust protection against potential DDoS attacks to ensure better service reliability and security.Key Improvements:- Enhanced Invalid Endpoint Handling - Better error responses and logging for requests to non-existent endpoints, helping developers quickly identify and fix integration issues
- Improved Input Validation - More comprehensive validation of API parameters with clearer error messages when invalid data is submitted
- DDoS Mitigation - Advanced rate limiting and traffic analysis to detect and mitigate potential distributed denial-of-service attacks
- Faster Error Responses - Optimized error handling pipeline reduces response times for invalid requests, improving overall API performance
- Better Error Documentation - Enhanced error codes and messages to help developers understand and resolve issues more efficiently
📝 Font Extraction Migration - Use Style Guide Endpoint (July 3rd)
If you’re currently using the retrieve endpoint to extract font information from domains, we recommend migrating to our new style guide endpoint for enhanced typography data.Why Migrate?- More Comprehensive Typography Data - Get detailed font specifications including font families, sizes, weights, line heights, and letter spacing for all heading levels (H1-H4) and body text
- Better Performance - The style guide endpoint is optimized for design system extraction with faster response times
- Future-Proof - This endpoint will receive ongoing improvements for typography and design system extraction
- Enhanced Accuracy - More sophisticated font detection and analysis algorithms
🚀 Infrastructure Performance Upgrade (July 2nd)
We’ve been working to make our style guide and screenshot APIs faster and higher quality. We added distributed caching, so repeat requests to the same domain are under 500ms. We also completely rewrote our style guide extraction and screenshot generation pipelines to be much more efficient, resulting in 40-60% faster response times across both APIs for cold hits.📸 Screenshot API Beta Launch (June 20th)
Screenshot API Now Live (Beta): We’re excited to announce our new Screenshot API, now available in beta! This endpoint allows you to capture high-quality screenshots of any website programmatically, perfect for building visual brand libraries, competitive analysis tools, or automated documentation systems.Key Features:- Flexible Screenshot Types - Choose between visible-page screenshots (standard browser view) or full-page screenshots that capture all content
- CDN-Hosted Images - All screenshots are automatically uploaded to our fast, reliable CDN and returned as direct URLs
- Simple Integration - Just provide a domain and optionally specify full-page capture
- High Quality Output - Professional-grade screenshots ready for immediate use
- Visual Brand Libraries - Automatically capture and archive website designs for brand analysis
- Competitive Intelligence - Monitor competitor website changes and design evolution over time
- Client Presentations - Generate current website screenshots for proposals and presentations
- Documentation & Reports - Include live website visuals in automated reporting systems
- Quality Assurance - Capture website states for testing and comparison workflows
- Portfolio Creation - Build visual portfolios showcasing website designs and layouts
🎨 Style Guide API Beta Launch (June 19th)
Style guide API now live (beta): We’re excited to announce our new design system and style guide API, now available in beta! This powerful endpoint automatically extracts comprehensive design system information from any brand’s website, giving you instant access to their visual DNA.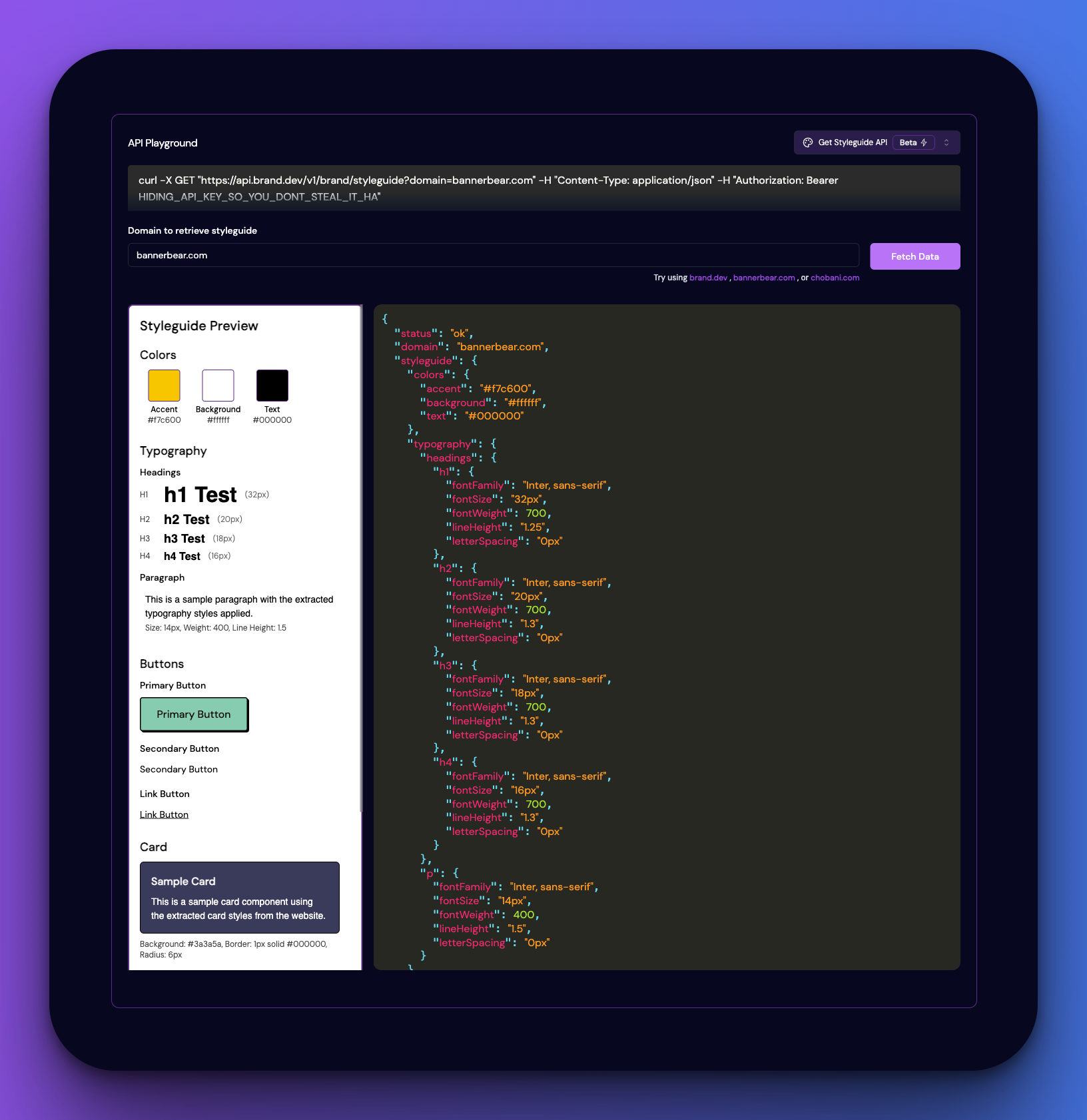 What You Get:
What You Get:- Color Palette - Primary colors including accent, background, and text colors
- Typography System - Complete font specifications for headings (H1-H4) and body text including font families, sizes, weights, line heights, and letter spacing
- Spacing Scale - Standardized element spacing values (XS through XL)
- Shadow System - Box shadow definitions from subtle to dramatic effects
- Component Styles - Detailed styling for buttons (primary, secondary, link) and cards with all CSS properties
- SaaS Dashboard Personalization - Automatically adapt your B2B software’s UI colors, fonts, and styling to match each client’s brand identity
- White-label Product Customization - Instantly extract and apply client branding to create seamless white-label experiences
- Personalized Email Campaigns - Use extracted styleguide colors and typography to create branded email templates that resonate with each prospect
- Custom Onboarding Flows - Dynamically style your onboarding experience to match new users’ company branding for higher engagement
- Sales Demo Personalization - Automatically theme your demo environment with prospect’s styleguide colors and fonts for more compelling presentations
- Client Portal Branding - Extract design systems to create branded client portals that feel like an extension of their own website
🎯 Developer Portal & Affiliate Program (June 12th)
- Developer Portal Design: We’ve completely revamped the developer portal with a modern, intuitive interface that better reflects our brand identity. The new design features improved navigation, enhanced documentation readability, and a more cohesive visual experience across all pages.
- Affiliate Program Launch: We’re excited to announce our new affiliate program! Earn 20% commission on all referrals when you help others discover the power of our API. Perfect for developers, agencies, and businesses looking to monetize their network while sharing valuable tools. Click here to sign up in 60 seconds or less.
⚡ Performance Improvements (June 11th)
Data pipeline has been improved dramatically, on-demand API latency has dropped by 30% across the board.🚀 Preload Endpoint Launch (June 10th)
Preload endpoint now live: Our new preload endpoint is now available for all paid customers! This powerful optimization tool allows you to signal that you may need brand data for a particular domain soon, dramatically improving response times for subsequent API calls.Key Features:- Zero usage cost - Preload calls are completely free for subscribed customers
- Lightning-fast subsequent calls - Pre-warm our systems for instant data retrieval
- Perfect for user onboarding - Queue preload work as soon as a user signs up for optimal experience
- Simple integration - Just POST to
/brand/prefetchwith the domain
- Pre-load brand data during user registration flows
- Optimize performance for high-priority domains
- Reduce latency in real-time applications
- Enhance user experience with instant data availability
🎛️ New API Parameters for Enhanced Control (June 8th)
We’ve added two powerful new parameters to give you more control over your API requests:maxSpeed Parameter (Fetch Brand endpoint only):- Optional boolean parameter that optimizes API calls for maximum speed
- When set to
true, the API skips time-consuming operations for faster response - Perfect for use cases where speed is prioritized over comprehensive data collection
- Trade-off: Faster response times at the cost of less detailed information
timeoutMS Parameter (All endpoints):- Optional timeout control in milliseconds for all API requests
- Set custom timeout values from 1ms up to 300,000ms (5 minutes maximum)
- Requests exceeding the specified timeout will be aborted with a 408 status code
- Ideal for applications with strict response time requirements or custom retry logic
🤖 AI Query API Release (June 6th)
AI Query API released: Our AI Query API is now officially live! This powerful new endpoint allows you to intelligently extract and query specific information from any website without the technical complexity of web scraping.Perfect for populating customer accounts with key business information such as:- Use cases and service offerings
- Case studies and success stories
- Mission statements and company values
- Legal frameworks and compliance information
- Team information and company background
- Product details and specifications
- No need to build complex scraping infrastructure
- Handles dynamic content and JavaScript-heavy sites
- Bypasses common bot detection systems
- Returns clean, structured data ready for integration
- Perfect for onboarding automation and data enrichment workflows
📊 API Call History Improvements (June 5th)
We’ve released an improved API call history widget to the dashboard with enhanced filtering options. You can now filter your API calls by time periods including this month, last 3 days, last 7 days, last 3 months, last 6 months, last year, or view all time data for comprehensive historical analysis.
🔗 Automation Integration (May 30th)
Automation integration is now live!Note: This is a v0 launch; we only released the retrieve endpoint for now with the rest to follow soon.💎 Ruby SDK & Image Mode Updates (May 29th)
- New Ruby SDK released: https://rubygems.org/gems/context.dev
- Docs updated to show SDK usage
- We now return a third value for “mode” under images: has_opaque_background, this means the image has its own background and can be used in dark mode or light mode.